Fantasy Football System Design
Introduction: Game Event Stream Processing
Fantasy Football is a popular speculatory game intended as a friendly competition between American football fans. Groups of individuals, forming Fantasy Football “leagues”, imitate National Football League (NFL) organizations as they draft players and set rosters before each weekly matchup. Football players earn points based on their real-life performance - these points are then accumulated by users who claimed such players on their rosters. The objective is simple - solidify a roster to earn as many points as possible over the following week.
Several sports media companies offer app-driven Fantasy Football experiences, though, under the hood, intricate software architecture is imperative to driving a robust user experience.
This piece aims to explore crucial design decisions, system design principles, and technology and tooling considerations that fulfill the business needs of Fantasy Football platforms from the perspective of a sports media company.
Requirement Analysis
Context
- Up to 10 simultaneous games, each transmitting events every 3s, on average, though transmissions may be back-to-back.
- 90% of users reside in North America or Western Europe.
- Play results and events may change, for example, if overturned by a challenge or nullified by a penalty.
- Data platform must act as the source of truth for all football data, also supporting other user-facing solutions such as play-by-play or sports betting interfaces.
Technical Demands
- Points and statistics must be objectively accurate and up to date
- Zero data loss policy
- System-wide fault tolerance and downtime recovery
Scope and Simplicity
Football, and sports more generally, are complex to model in full. For simplicity’s sake, let us only track snaps, passes, runs, tackles, and touchdowns. Outside of direct gameplay, challenges and penalties will be considered. Assume all contextual game and player data is already populated.
Stream Management and Usage
The Scorer’s Box
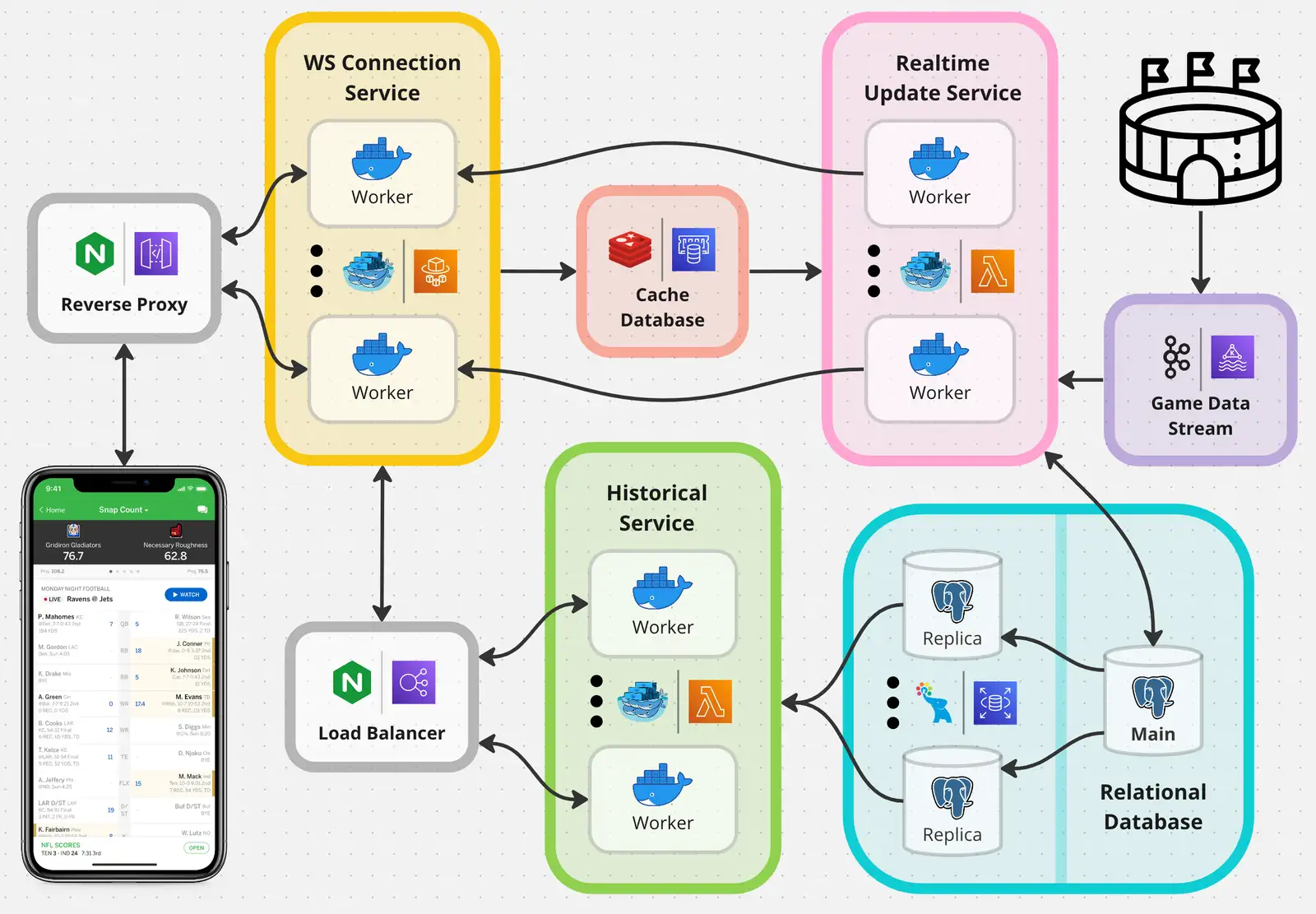
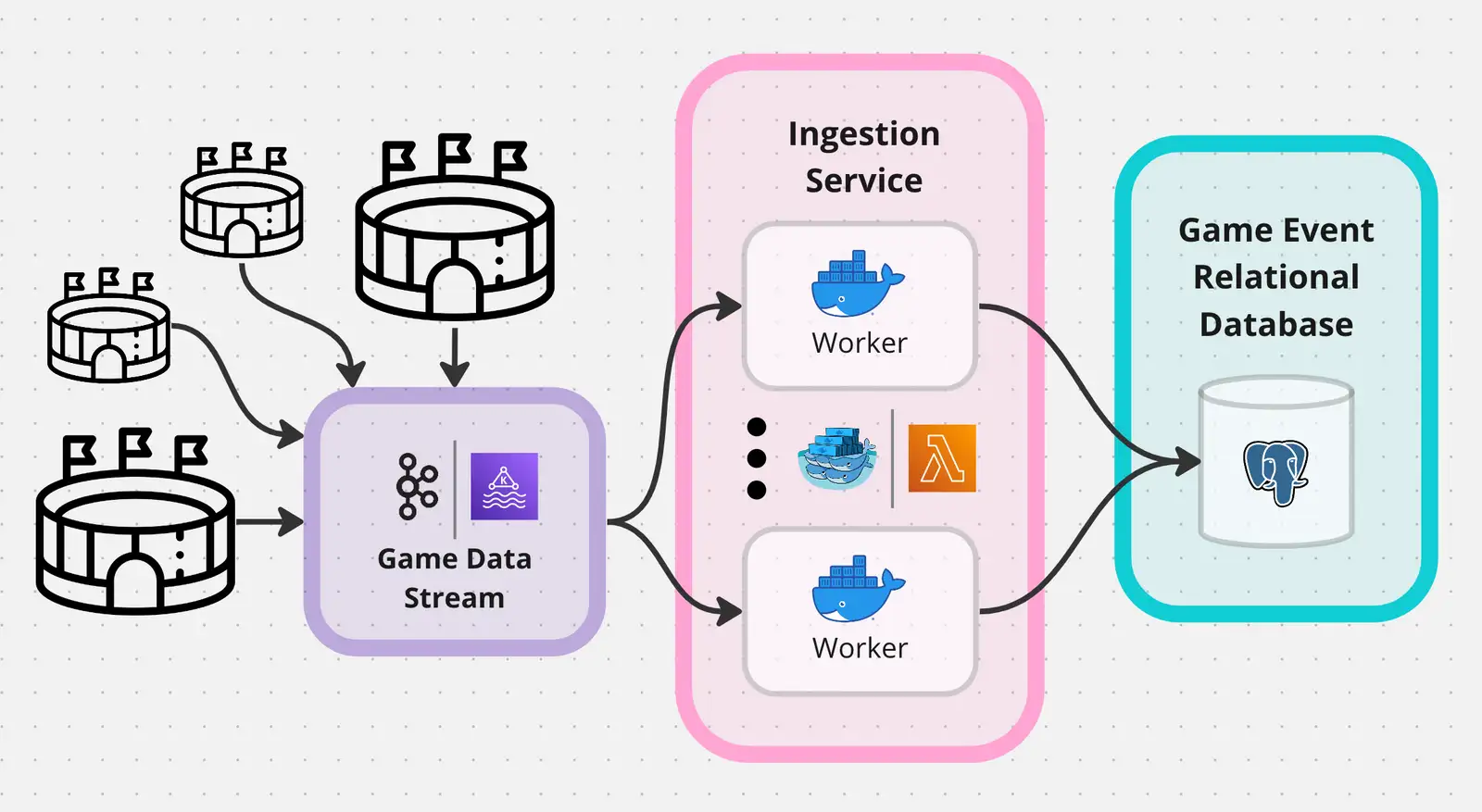
At the game’s stadium, an official scorer inputs a complete sequence of play-by-play events into the Game Data Stream. This data queue is a foundational component of the business, as many other orthogonal services and platforms may subscribe to the scorer’s published updates for their own respective needs.
At a scorer’s fingertips is an interface that establishes a unique gameID, playNumber, and eventNumber. gameID is an unambiguous identifier for the match being scored. playNumber is a counter that increments after each play. Similarly, eventNumber is a counter that increments after every submitted event, since events are published sequentially and synchronously. These three values allow the scorer to reference specific plays (following a snap) on top of which multiple specific events may occur. Later on, eventNumber will be especially necessary for handling game revisions resulting from overturned calls or penalties.
Apache Kafka
Apache Kafka is the chosen Publisher-Subscriber queue technology because of its robust buffer policy. Messages are written to high-throughput topics backed by log files. Each subscriber manages its location in the queue, thus able to catch up at its own pace and even replay previous messages in order if needed - since this buffer is the entrance of event data into our backend, consumption retries and behavior reproducibility are paramount in case of bugs or downtime.
To be safe, this topic will persist messages for a week, after which they will be archived in blob file storage. Also, we can configure Kafka to distribute topic logs across multiple partitions, each on a different broker, and replicate for durability. Proactively, if a broker goes down, the topic will still be available for consumption and any temporarily lost data can be recovered from its copy.
Finally, Kafka’s log file design guarantees at-least-once delivery. When a consumer successfully receives a message, it will acknowledge the delivery and update its new queue offset. When consumption failure occurs, the acknowledgment is not sent and Kafka attempts retransmission. This is not as ideal as exactly-once delivery, but it at least ensures that data loss is a nonpossibility; the only drawback is implementing the safe handling of duplicate messages.
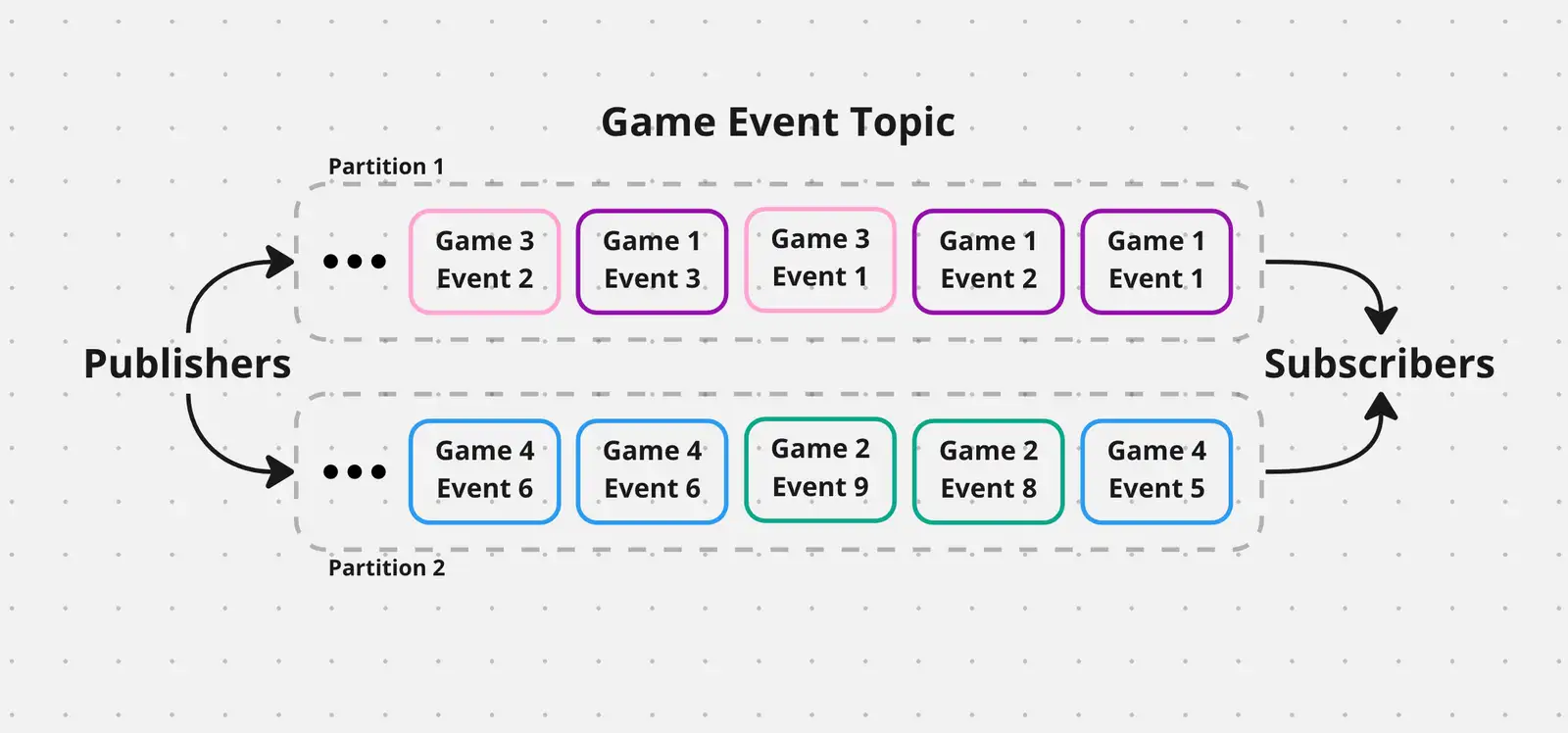
Stream Organization
Events must be consumed in the order of transmission to accurately depict game state. However, ordering is only necessary for events within a single game. To ensure this, we first require scorers to register or declare a unique gameID before the start of each game. Then, we configure Kafka to balance events between partitions by gameID, thus guaranteeing that all events for a single game are read in relative order. This is useful when replaying past events in the case of an error. By contrast, if events from simultaneous games are woven together uniformly across all partitions, the relative order of same-game events is jeopardized.
Kafka partitions allow for messages to be split between multiple consumers. Thus to prepare for maximum consumer scalability, the more partitions, the marrier. However, since there are only ever 10 simulatanous games each emmitting events every 3 seconds, there is no signmificant need for further partition orchestration.
Ingestion Service
When the scorer speaks, the Ingestion Service listens. It employs a scalable cluster of processing workers that transform incoming messages into actionable outcomes. In this case, upon receiving a new game event through Kafka, corresponding database entries are created.
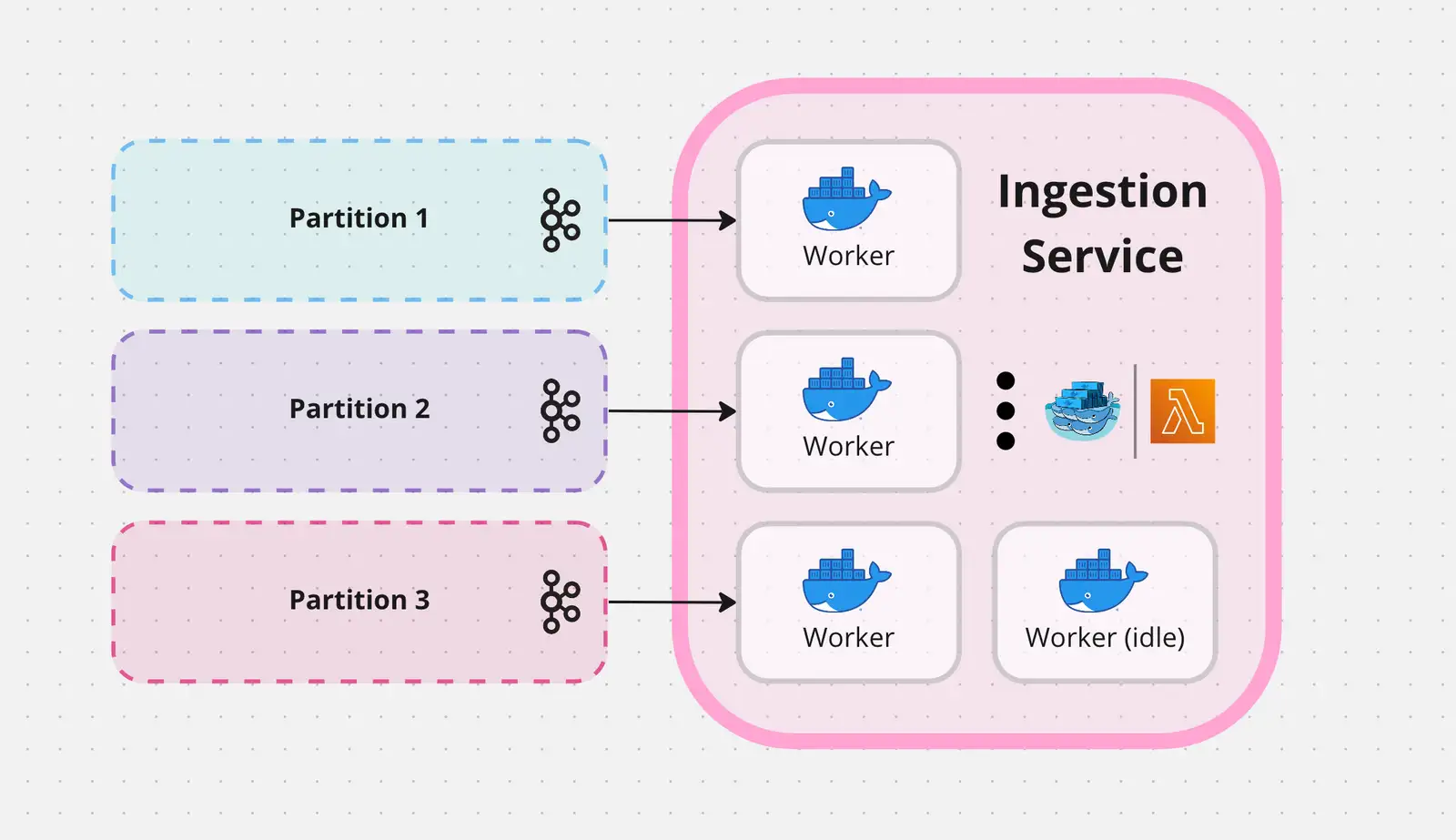
The simplest solution is to spin up a few compute instances to form a consumer group across all partitions. The incoming message load can be divided and conquered by the finite compute instances, but this approach does not scale to message volume.
Alternatively, we may deploy a horizontally scalable cluster of general event ingestion workers. Like before, these workers form a consumer group to optimally distribute incoming messages. If a worker goes down, more are already running and will take on a temporarily heightened load until the replacement node spins up. Additionally, the number of workers may be scaled during gametime. But this method is not perfect. We will need more advanced logic to handle out-of-order data operations - in other words, when batch 2 begins before batch 1 completes since events are ingested asynchronously. Though more complex, this method allows us to achieve the stated goals with some clever software design.
Because each consumer must commit consumption acknoledgements to the Kafka partition it reads from, the number of performing concurrent workers is limited by the number of partitions. Any more than this breaks the data consumption guarantee by greedily reading ahead before knowing if the current read succeeds. Therefore, as hinted at before, the more partitions, the better. Excess workers are idle, though a few extra instances are beneficial for immediate failover.
Container Orchestration and Scalability
As mentioned, workers are designed to be horizontally scalable to fit variable demand. This is accomplished by orchestrating a cluster of Docker containers, each running an instance of the ingestion service. Docker Swarm provides stable cluster network configuration and scalability basics. Kubernetes is the Swiss-Army knife of advanced container orchestration, though it is overkill for our design. A simple Docker contrainer scheduler based on the game schedule will suffice.
Data Modeling, Organization, and Operations
Our data space consists of known, fixed-schema entities, between which are one-to-one, one-to-many, or even many-to-many relations. For instance, one play may be linked to 3 tackles, but only one touchdown can occur per play. A relational database fits our needs.
The Relational Model
Beyond drawing lines between entities, the relational model brings many bonuses. Key and Referential Integrity constraints ensure that the data being added belongs - unwanted duplicates and invalid relationships are avoided altogether, by design. Since entity schema is known, an RDBMS may intelligently apply optimal memory layout and compression to best fit the given column datatypes or leverage consistent data patterns. And of course, ACID compliance is wonderful for ensuring expected behavior. But which database to use? PostgreSQL is an open-source RDBMS with many modern features (for future product growth) available out of the box or through plugins - a clear top choice.
Data Entity Constraints
There exists a scenario where an ingestion process fails, after which the Kafka queue must rewind to ensure the missed data is retried. However, each unique event should only be handled once. The secret here is to enforce idempotency - meaning operations applied over and over should equate to the same operation only applied once. For this reason, only insertion operations occur and each entity has its Key Integrity constraints to ensure duplicate insertions are rejected. Direct row modification is reserved for overturned calls and manual intervention to correct a scorer’s error.
Note that in this example, Referential Integrity constraints are ignored because every event has a unique gameID, playNumber, and eventNumber with concesous maintained by the scorer - not a member within the database. Even if database insertions occur slightly out of order due to execution time variability, we can trust that dependent rows will soon be inserted instead of rejecting eager writes altogether. To illustrate, if a pass is written before the snap, we allow the snap to be lazily inserted shortly after instead of unnecessarily rejecting the pass insertion, blocking for the snap insertion, then retrying the pass insertion.
Handling Overturned and Reversed Calls
Event handling is a straightforward process until events are overturned by challenges or penalties. The original event cannot be erased from the historical timeline of the game, though must be marked as invalidated in favor of a new ruling.
But did we not establish that row modification is a no-no? Yes, though this case presents an exception while retaining operation idempotency. Let us add a valid column to each event’s schema. Upon initial row insertion, this value defaults to true. If the event is overturned, the valid entry is set to false, and cannot ever become true again. Simply put, this does break our rule of no modification, but since modifications are unidirectional and applied to previously unset fields, no previous data is overwritten - our main intent.
Yet a simple valid column is not enough. This is only satisfactory when an event is nullified. For instance, a touchdown pass may be nullified after Offensive Pass Interference is called. The entire play resets with a less favorable field position for the offense. However, there are times when an event is entirely overridden by a different outcome, such as a 60-yard run overturned to a 40-yard run following a successful review. In these cases, the event’s current row is invalidated and a newly updated entry is inserted. Thus, for a given entity, each event will have at most one valid row, allowing valid plays to be retrieved without duplication.
Planning ahead, if future rules allow for an event to be overturned multiple times, our design still accurately depicts the scenario: just invalidate the only valid entry for that event (could be the original or previously corrected), and insert the corrected row.
Proposed Entities
Below, we materialize these ideas into concrete schemata.
Plays
| gameID | playNumber | eventNumber | startTimestamp | gameSecondsPlayed | posession | fieldPosition | down| | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- |----------- | | bfjsu | 1 | 1 | 1671127112555 | 15 | SF | 24 | 1 | | … | … | … | … | … | … | … | … | … | … | … | … | … | | bfjsu | 90 | 321 | 1671127114134 | 1304 | ATL | 56 | 3 |
Passes
| gameID | playNumber | eventNumber | passerID | throwYard | receptionYard | recieverID | isTouchdown | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- | — | - | | bfjsu | 4 | 8 | jiglp | 2 | 10 | jkhne | false | | bfjsu | 12 | 19 | jiglp | 50 | 60 | gnslw | true | | … | … | … | … | … | … | … | … | … | … | … | … | … |
Tackles
| gameID | playNumber | tacklerID | tackledID | fieldPosition | valid | | ------ | ---------- | --------- | --------- | ------------- | ----- | --- | --- | --- | --- | | bfjsu | 1 | nvhew | ndjks | 27 | true | | bfjsu | 2 | kfnsw | bkjwe | 30 | true | | bfjsu | 2 | nvhew | zokjf | 0 | true | | … | … | … | … | … | … | … | … | … | … |
Runs
| gameID | playNumber | eventNumber | playerID | startYard | endYard | isRush | isTouchdown | valid | | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- | — | - | - | | bfjsu | 4 | 7 | jkhne | 10 | 25 | false | false | true | | bfjsu | 7 | 14 | lksqs | 25 | 40 | true | false | true | | bfjsu | 8 | 20 | nxmze | 40 | 100 | true | true | false | | bfjsu | 8 | 20 | nxmze | 40 | 90 | true | false | true | | … | … | … | … | … | … | … |… | … | … | … | … | … | … |
With these simplified entities, basic football plays can be tracked and queried for insight. Below are a few relevant queries that could be useful within our Fantasy Football use case.
Proposed Queries
The notion of “raw” events in the database successfully captures the complete story of each game, though passes complexity to the data consumer; in reality, this is no issue since queries themselves are static in nature. In other words, a more complex query can be written once and never again.
- Find a player’s rushing yards for a given game
select sum(endYard - startYard) from Runs
where playerID = ... and gameID = ... and valid = true;- Find a player’s passing yards for a given game
select sum(throwYard - receptionYard) from Passes
where passerID = ... and gameID = ... and valid = true;- Find a how many solo tackles are attributed to a player for a given game
select count(*) from (
select count(*) from Tackles
where valid = true and gameID, playNumber in
(select gameID, playNumber from Tackles
where tacklerID = ... and gameID = ... and valid = true)
group by gameID, playNumber
having count(*) = 1
) soloTackles;- Find all touchdown timestamps for a given game, and the players credited
select startTimestamp from (
select playNumber from Passes
where gameID = ... and touchdown = true and valid = true
union
select playNumber from Runs
where gameID = ... and touchdown = true and valid = true
) touchdowns
join Plays on touchdowns.playNumber = Plays.playNumber;Out-of-Order Data Operations
Due to extreme network or program conditions, an original event can be written to the database after its correction. This is a rare occurrence, but we must be prepared to handle it. Even worse, the out-of-order process to nullify and overturn events are separate.
One approach is to accept all incoming writes and scan for an event’s corrections before the insertion of the original event. Essentially assuming all writes are out of order, every write will follow an expensive read to determine if the prerequisite or correction row exist - performance will be constantly impacted for a scenario rarely encountered. This also does not handle the case of nullifying an event before its original insertion, as it is impossible to modify a nonexistant row. An additional layer of event management is required.
A better approach is to not complicate writing patterns at the expense of infrequent inefficiencies. Instead, assume all data is written in order, and only apply the scan when inserting the less frequent call reversals. Before nullifying or overturning an event, check if the prerequisite row exists. If it does, the operation completes like before. If not, wait 50ms or so for a parallel process to complete the original event insertion, then try again. As stated, this may lead to a slight increase in event insertion latency following official reviews, but keep general performance at its optimum.
In SQL, let us demonstrate the improved writting pattern for a Run event.
- Insert an
Runevent
insert into Runs values (...);- Nullify the
Runevent
update Runs
set valid = false
where gameID = ... and playNumber = ... and eventNumber = ...
returning eventNumber;
/* if no rows are returning, retry from the ingestion service worker after a brief timeout. */- Overturn the
Runevent
begin
update Runs
set valid = false
where gameID = ... and playNumber = ... and eventNumber = ...;
if not found raise exception 'Original event not found';
insert into Runs values (...);
end;
/* on catching the exception from the ingestion service worker, retry after a brief timeout. */Realtime Client Delivery, Caching, and Querying
To be continued…